Method
Overview
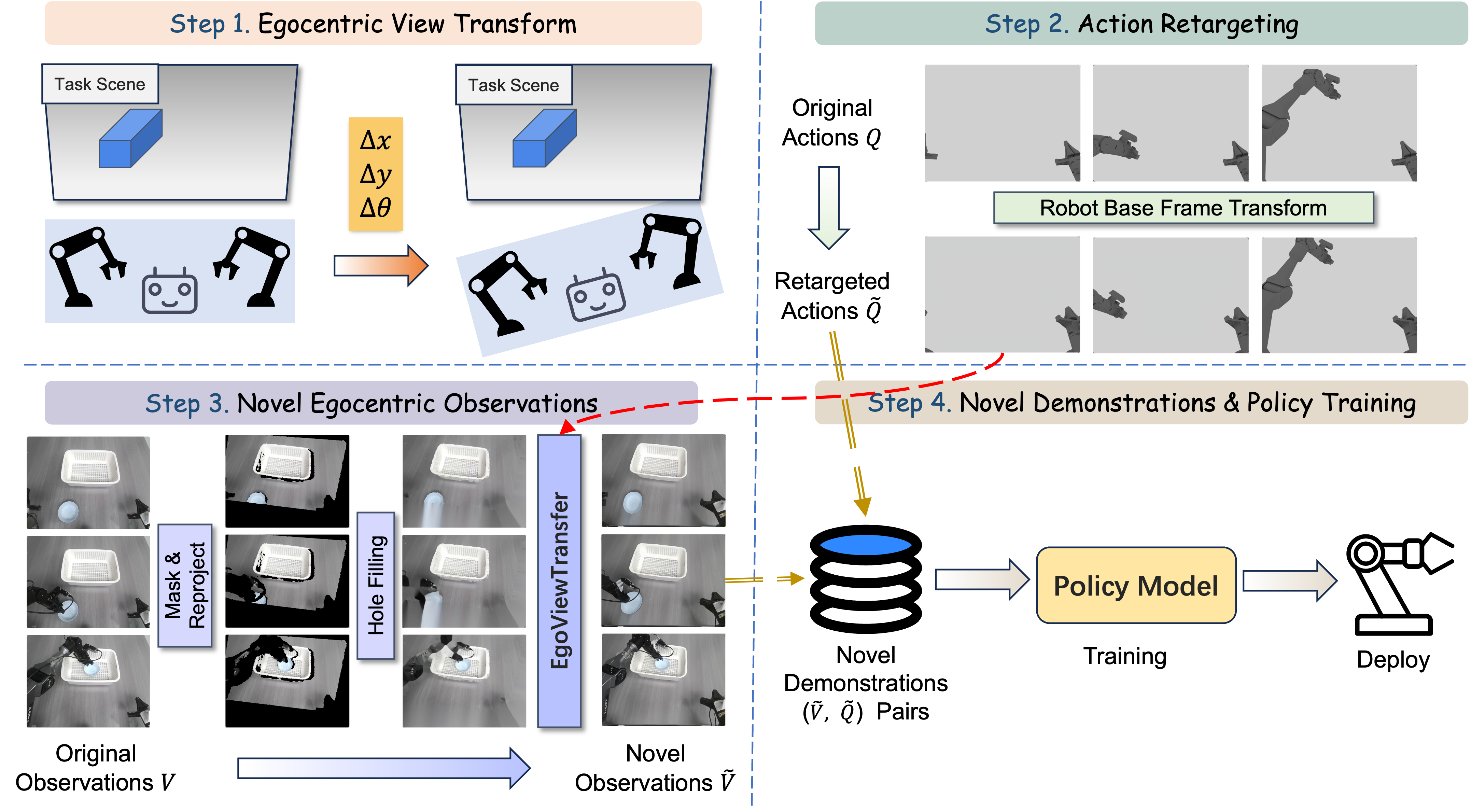
Framework of EgoDemoGen.
Overview of EgoDemoGen. (1) Egocentric View Transform: a Novel Egocentric View is specified by robot base motion \((\Delta x,\ \Delta y,\ \Delta \theta)\). (2) Action Retargeting: the original joint actions \(Q\) is retargeted into the novel robot base frame to yield a kinematically feasible joint actions \(\tilde{Q}\). (3) Novel Egocentric Observations: starting from the original observation video \(V\), we mask the robot, reproject the scene to the novel viewpoint, perform hole filling, and apply EgoViewTransfer to synthesize the coherent observations \(\tilde{V}\). (4) Novel Demonstrations & Policy Training: we obtain aligned pairs \((\tilde{V},\ \tilde{Q})\) for training egocentric viewpoint-robust policies.
EgoViewTransfer
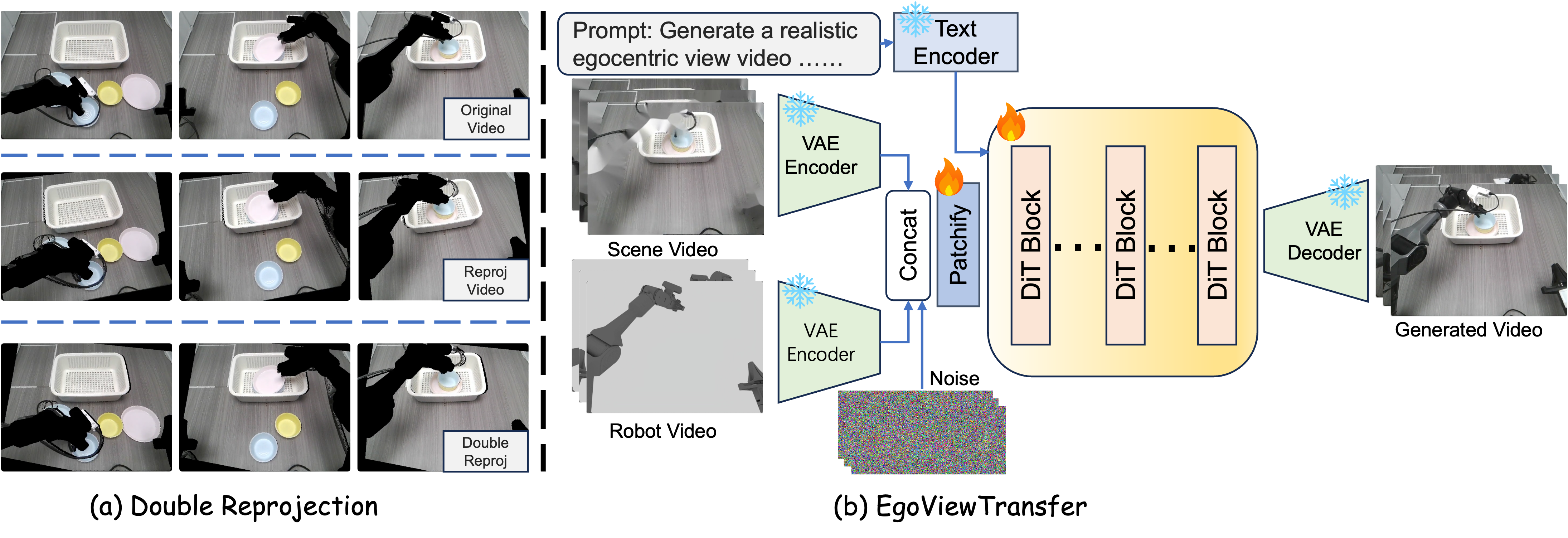
Architecture of EgoViewTransfer.
EgoViewTransfer. (a) Double reprojection. It simulates artifacts and occlusions caused by viewpoint change. The double reprojected video are aligned with the original video to form input/label pairs for training. (b) Architecture of EgoViewTransfer. The model takes a degraded scene video and a robot video as conditions and generates egocentric observation videos consistent with dual inputs.

